ML — Recurrent Neural Network: Bar-to-Bar Memory for NinjaTrader 8
Every model in this series so far — k-Nearest Neighbors, online logistic regression, the single– and multi-hidden-layer nets, and last post’s Adam-trained version — has shared one quiet limitation. Each prediction sees only the current bar’s feature vector. If a pattern depends on what the market did five bars ago, that information has to be explicitly hand-encoded as a feature, or the model never sees it at all.
This post removes that limitation. A Recurrent Neural Network (RNN) keeps a hidden-state vector that carries forward from bar to bar. Each prediction is a function of the current bar and everything the hidden state has accumulated — so the model can, in principle, learn patterns that span many bars without you naming them in advance. Training that recurrent loop needs a new tool: truncated Backpropagation Through Time (BPTT). That, and its famous failure mode — the vanishing gradient — are what this post is about.
🧠 Feedforward vs RNN — What Memory Adds
A feedforward network is a pure function: features go in, a prediction comes out, and nothing is retained between calls. Two bars with the same feature vector always produce the same prediction, no matter what happened before them. An RNN breaks that by routing the hidden state back into itself.
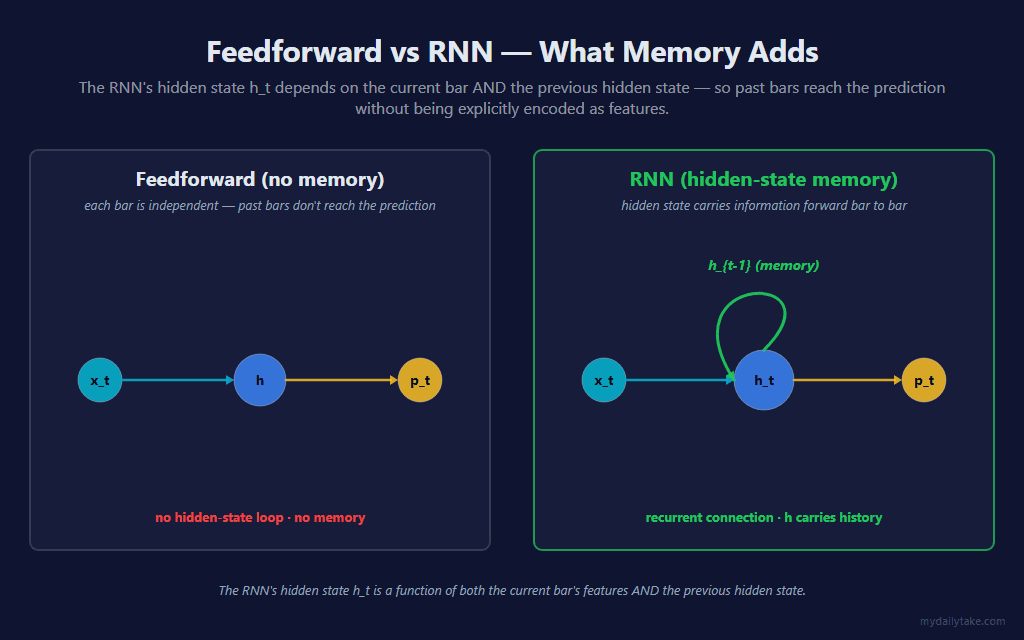
The whole difference is that loop. The RNN’s hidden state at bar t is computed from two inputs: the current bar’s features and the hidden state from bar t−1. Written out, the recurrent step is:
h_t = tanh( Wxh · x_t + Wrec · h_{t-1} + bh )
Wxh is the input-to-hidden weight matrix — the same role it played in the feedforward nets. Wrec is new: the recurrent hidden-to-hidden matrix that decides how much of the previous hidden state survives into the current one. The tanh is not cosmetic — it bounds the hidden state to the range [−1, 1] every step, which is what stops the recurrent loop from amplifying its own output into infinity. The prediction itself is the same sigmoid output head from the feedforward posts, reading the final hidden state: p = sigmoid( Wo · h + bo ).
🕰️ Unrolling the Network Through Time
The RNN is physically one cell with one set of weights. But the cleanest way to reason about it — and the only way to train it — is to picture that single cell stamped out once per bar, with the hidden state flowing left to right along the chain. That picture is called the unrolled network.
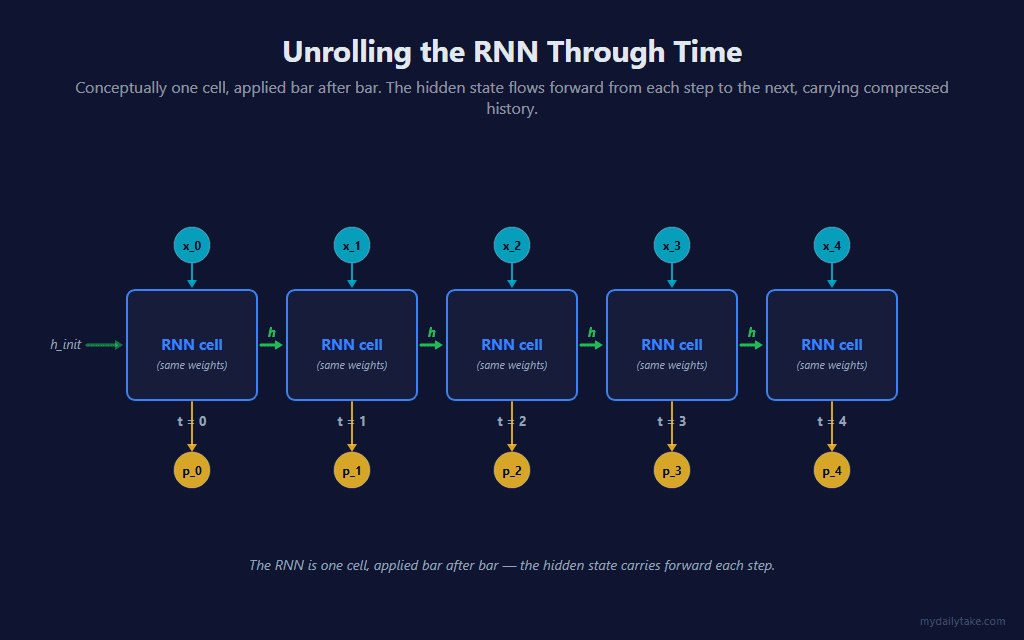
Two things are worth pinning down in that picture. First, every box is the same cell — the weights Wxh, Wrec, bh, Wo, bo are shared across all time steps. There is no separate “bar-3 weight.” Second, the only thing connecting one step to the next is the hidden state vector h. It is the entire memory of the network — a fixed-size summary of everything seen so far, compressed into HiddenSize numbers.
This indicator actually runs two separate copies of that walk. A live hidden state walks forward bar by bar, indefinitely, and produces the prediction you see on the chart. A training walk is rebuilt from scratch on every training-eligible bar over a short fixed window — that second walk is what BPTT operates on. Keeping them separate means training never disturbs the live prediction’s state.
➡️ The Forward Step
The forward computation is small. StepHidden advances the hidden state one bar; OutputSigmoid reads a hidden state and produces the probability. The previous hidden state is snapshotted before the update so that, as the new values are written element by element, every neuron still reads a consistent copy of h_{t-1}:
// One forward step. StepHidden advances the hidden state by one bar:
// h <- tanh(Wxh . x + Wrec . h_prev + bh)
// The previous hidden state is snapshotted into hPrevScratch first, so every
// neuron reads a consistent copy of h_prev while the new values are written.
private void StepHidden(double[] h, double[] x)
{
for (int j = 0; j < HiddenSize; j++) hPrevScratch[j] = h[j];
for (int hh = 0; hh < HiddenSize; hh++)
{
double z = bh[hh];
for (int k = 0; k < NumFeatures; k++) z += Wxh[hh][k] * x[k];
for (int j = 0; j < HiddenSize; j++) z += Wrec[hh][j] * hPrevScratch[j];
h[hh] = Math.Tanh(z);
}
}
// The output head reads a hidden state and produces P(up) via the sigmoid.
private double OutputSigmoid(double[] h)
{
double z = bo;
for (int hh = 0; hh < HiddenSize; hh++) z += Wo[hh] * h[hh];
return Sigmoid(z);
}
That is the entire forward pass. The live prediction calls StepHidden once per bar on the persistent hidden state, then OutputSigmoid on the result. Training calls StepHidden repeatedly to rebuild the unrolled window — which is where backpropagation comes in.
🔁 Backpropagation Through Time
Training a feedforward net is one forward pass and one backward pass. Training an RNN is harder, because the weights are reused at every time step — a single weight influenced the prediction once per bar in the window. Its gradient is therefore a sum of contributions from every step. BPTT is the bookkeeping that collects that sum.
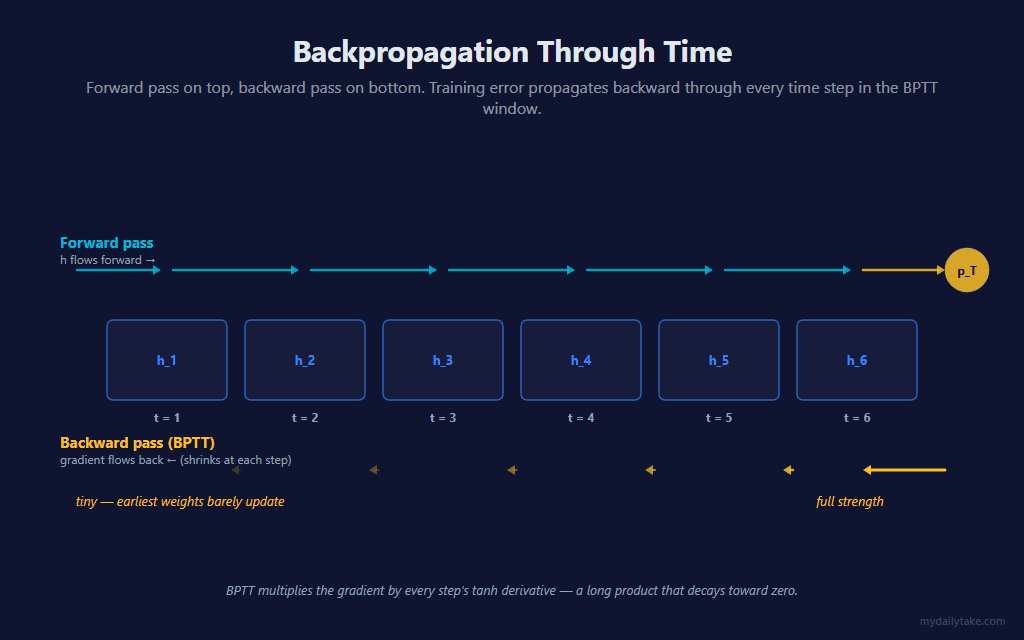
The forward direction recomputes the hidden state across the window. The backward direction starts at the output error and walks the chain in reverse, and the per-step math is the same chain rule used in every prior post:
- Output error. With a sigmoid output and cross-entropy loss, the gradient at the output collapses to
error = p − y— the same clean simplification from the logistic-regression post. - Through the tanh. The gradient entering hidden step t is scaled by the tanh derivative:
dz_t = dh_t · (1 − h_t²). - Into the weights. Each step adds to the shared gradient accumulators:
Wxhgetsdz_t · x_t, the recurrent matrixWrecgetsdz_t · h_{t-1}, the bias getsdz_t. - Back one more step. The gradient is pushed to the previous hidden state through
Wrectransposed — and the loop repeats.
// TRUNCATED BPTT — recompute the forward pass over the BpttWindow bars ending
// at trainBar, then backprop the gradient through every time step in that
// window. The "anchor" hidden state at the start of the window is reset to
// zero each call — a standard simplification for online truncated BPTT. The
// live persistent state (hLive) is untouched; it walks forward independently.
//
// Window indexing (the feature ring is 0 = newest):
// trainBar lives at ring index LabelHorizon.
// The window covers ring indices (LabelHorizon + BpttWindow - 1) down to
// LabelHorizon — BpttWindow bars, with trainBar at the right (newest) end.
private void TruncatedBptt(double y)
{
// Forward pass over the BPTT window.
// hSeq[0] = anchor (zero); hSeq[t+1] = hidden state after processing bar t.
for (int j = 0; j < HiddenSize; j++) hSeq[0][j] = 0.0;
for (int t = 0; t < BpttWindow; t++)
{
int ringIdx = LabelHorizon + BpttWindow - 1 - t; // oldest first
double[] xt = featureRing[ringIdx];
double[] hPrev = hSeq[t];
double[] hCur = hSeq[t + 1];
for (int hh = 0; hh < HiddenSize; hh++)
{
double z = bh[hh];
for (int k = 0; k < NumFeatures; k++) z += Wxh[hh][k] * xt[k];
for (int j = 0; j < HiddenSize; j++) z += Wrec[hh][j] * hPrev[j];
hCur[hh] = Math.Tanh(z);
}
}
// Output and error at the end of the window.
double pTrain = OutputSigmoid(hSeq[BpttWindow]);
double error = pTrain - y; // dL/dzOut for cross-entropy + sigmoid
// Zero the gradient accumulators.
for (int hh = 0; hh < HiddenSize; hh++)
{
for (int k = 0; k < NumFeatures; k++) gWxh[hh][k] = 0.0;
for (int j = 0; j < HiddenSize; j++) gWrec[hh][j] = 0.0;
gbh[hh] = 0.0;
}
// Output-layer gradients (computed using OLD Wo before we update it).
// Also seed dhNext[h] = error * Wo[h] — gradient flowing back from the
// output into the LAST hidden state hSeq[BpttWindow].
for (int hh = 0; hh < HiddenSize; hh++)
{
gWo[hh] = error * hSeq[BpttWindow][hh] + RegularizationLambda * Wo[hh];
dhNext[hh] = error * Wo[hh];
}
double gbo = error;
// BPTT — walk backward through the unrolled time steps.
// dz_t = dh_t * (1 - h_t^2) [tanh derivative]
// gWxh[h][k] += dz_t[h] * x_t[k]
// gWrec[h][j]+= dz_t[h] * h_{t-1}[j]
// gbh[h] += dz_t[h]
// dh_{t-1}[j] = sum_h( Wrec[h][j] * dz_t[h] )
for (int t = BpttWindow; t >= 1; t--)
{
int ringIdx = LabelHorizon + BpttWindow - 1 - (t - 1);
double[] xt = featureRing[ringIdx];
double[] hPrev = hSeq[t - 1];
double[] hCur = hSeq[t];
for (int hh = 0; hh < HiddenSize; hh++)
dzScratch[hh] = dhNext[hh] * (1.0 - hCur[hh] * hCur[hh]);
for (int hh = 0; hh < HiddenSize; hh++)
{
double dzh = dzScratch[hh];
for (int k = 0; k < NumFeatures; k++) gWxh[hh][k] += dzh * xt[k];
for (int j = 0; j < HiddenSize; j++) gWrec[hh][j] += dzh * hPrev[j];
gbh[hh] += dzh;
}
// Propagate gradient to hPrev — uses OLD Wrec (weights update later).
// Skip at t == 1: hSeq[0] is the fixed zero anchor, no gradient flows past it.
if (t > 1)
{
for (int j = 0; j < HiddenSize; j++)
{
double s = 0.0;
for (int hh = 0; hh < HiddenSize; hh++)
s += Wrec[hh][j] * dzScratch[hh];
dhPrevScratch[j] = s;
}
for (int j = 0; j < HiddenSize; j++) dhNext[j] = dhPrevScratch[j];
}
}
// Apply weight updates — plain SGD, L2 on the weight matrices only.
for (int hh = 0; hh < HiddenSize; hh++)
{
for (int k = 0; k < NumFeatures; k++)
{
double grad = gWxh[hh][k] + RegularizationLambda * Wxh[hh][k];
Wxh[hh][k] -= LearningRate * grad;
}
for (int j = 0; j < HiddenSize; j++)
{
double grad = gWrec[hh][j] + RegularizationLambda * Wrec[hh][j];
Wrec[hh][j] -= LearningRate * grad;
}
bh[hh] -= LearningRate * gbh[hh];
Wo[hh] -= LearningRate * gWo[hh];
}
bo -= LearningRate * gbo;
}
One detail in that code deserves an honest callout. At the start of each training window the anchor hidden state — hSeq[0] — is reset to zero, rather than carried over from whatever the live model’s hidden state actually was at that point in history. This is a standard simplification for online truncated BPTT: it keeps every training step fully self-contained and reproducible. The cost is that the unrolled window always starts “cold,” with no inherited memory. In practice the first few steps of the window are mostly spent rebuilding context, which is one more reason — alongside the vanishing gradient below — that a very long BpttWindow delivers less than you might expect.
Note also that the weight updates are applied after the entire backward loop finishes, and the gradient propagated through Wrec always uses the old weight values. Updating weights mid-loop would corrupt the chain rule for every step still to come. Training here is plain stochastic gradient descent — one update per training-eligible bar — to keep the focus squarely on the BPTT gradient flow; the Adam optimizer from the prior post could be layered on top unchanged.
⚠️ The Vanishing Gradient Problem
Look again at the backward arrows shrinking step after step. That shrinkage is not a drawing choice — it is the central difficulty of training vanilla RNNs, and it is worth understanding precisely.
Each backward step multiplies the gradient by the tanh derivative, 1 − h². That term is at most 1.0, and for any hidden value that is not near zero it is well below 1.0 — commonly around 0.5 or less once the network is trained and its activations are doing real work. Multiply a number below one by itself enough times and it collapses toward zero.

Ten steps of a 0.5 multiplier leaves roughly one part in a thousand of the original gradient. So the weights, as they are reused at the oldest bars in the window, receive a training signal that is orders of magnitude weaker than the signal at the most recent bars. The network is not refusing to learn long-range structure — it simply receives almost no gradient telling it how. A vanilla RNN reliably learns short-range dependencies and struggles with anything much beyond a handful of bars.
This is not a bug to be fixed with a better learning rate. It is a structural property of multiplying many small numbers in a chain. The architecture that solves it — the LSTM, with a gated memory cell that lets gradients flow without being squashed every step — is the subject of the next post in this series. Understanding exactly why the vanilla RNN falls short is the best preparation for it.
🎚️ The BpttWindow Trade-Off
The BpttWindow parameter sets how many bars back the network is unrolled for each training step. Bars inside the window contribute gradients; bars outside it are invisible to training.
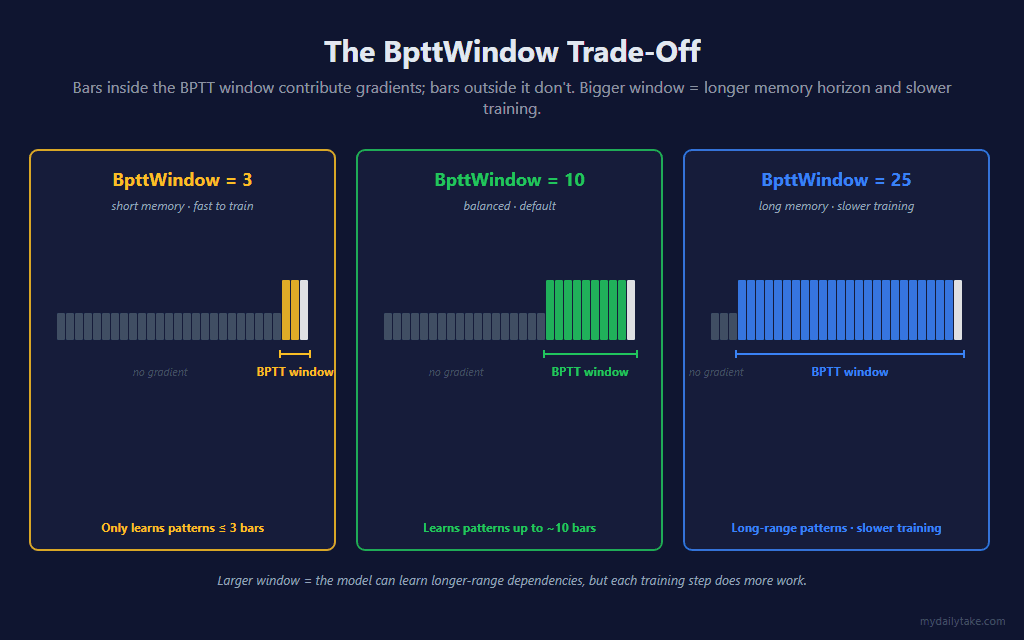
The naive reading is “bigger window = longer memory = better.” The vanishing gradient complicates that. A larger window does let gradients reach further back in principle — but the signal reaching those older bars has already been multiplied down to near nothing. So the extra bars cost real compute on every training step while contributing very little learning. BpttWindow = 10 is the default: long enough to capture genuinely useful short-range structure, short enough that every step in the window still receives a gradient worth the arithmetic. Drop it toward 3 for the fastest training and shortest memory; push it toward 25 only if you specifically want to test longer horizons — and read the chart section below before you assume it helps.
🔧 The Training Loop
Each bar, the indicator does four things in order: step the live hidden state forward for the prediction, push the new feature vector into a rolling ring buffer, run one truncated-BPTT training step if a label is now observable, and finally publish the outputs and check the signal gate. The ring buffer is sized exactly BpttWindow + LabelHorizon — enough history to rebuild the unrolled window and reach back to the bar whose forward outcome is now known:
// Inside OnBarUpdate, after the feature vector for the current bar is built.
// Four steps run in order on every bar:
// 1) Live forward step — advance the persistent hidden state, read P(up).
NormalizeInto(scratchNorm, scratchRaw, 0);
StepHidden(hLive, scratchNorm); // hLive <- tanh(Wxh.x + Wrec.hLive + bh)
double pUp = OutputSigmoid(hLive);
// 2) Push the new normalized feature into the ring buffer (index 0 = newest).
// The ring is sized BpttWindow + LabelHorizon — exactly enough history.
PushFeatureRing(scratchNorm);
// 3) Training step — once the buffer holds a full BPTT window AND the bar
// from LabelHorizon ago has an observable forward outcome.
int needForTraining = BpttWindow + LabelHorizon;
if (ringFilled >= needForTraining && CurrentBar >= predictionWarmup + LabelHorizon)
{
int trainBar = LabelHorizon;
bool trainThisBar = false;
double y = 0.0;
if (LabelMode == MlNeuralNetRnn_LabelMode.CloseToClose)
{
y = Close[0] > Close[trainBar] ? 1.0 : 0.0;
trainThisBar = true;
}
// (FavorableExcursion branch omitted here — see the Label Mode setting.)
if (trainThisBar)
TruncatedBptt(y); // one truncated-BPTT update
}
// 4) Publish the public-Series outputs for downstream strategies.
sProbabilityUp[0] = pUp;
sConfidence[0] = Math.Abs(pUp - 0.5) * 2.0;
The look-ahead safety mechanism is the same one used throughout the series: the model trains on the bar from LabelHorizon ago — whose realized direction is now genuinely observable — and predicts on the current bar. Nothing in the training path ever reads a price the live model would not have had. The ring buffer stores normalized feature vectors, so the BPTT window is reconstructed from exactly the inputs the network saw at the time.
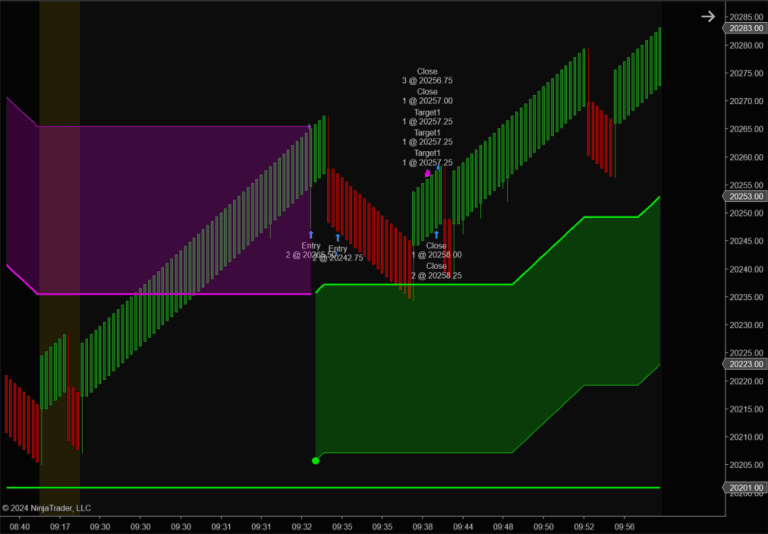
📊 What This Looks Like on a Chart
Same indicator, same NQ session, same features and labels. Only BpttWindow changes. First, the default:
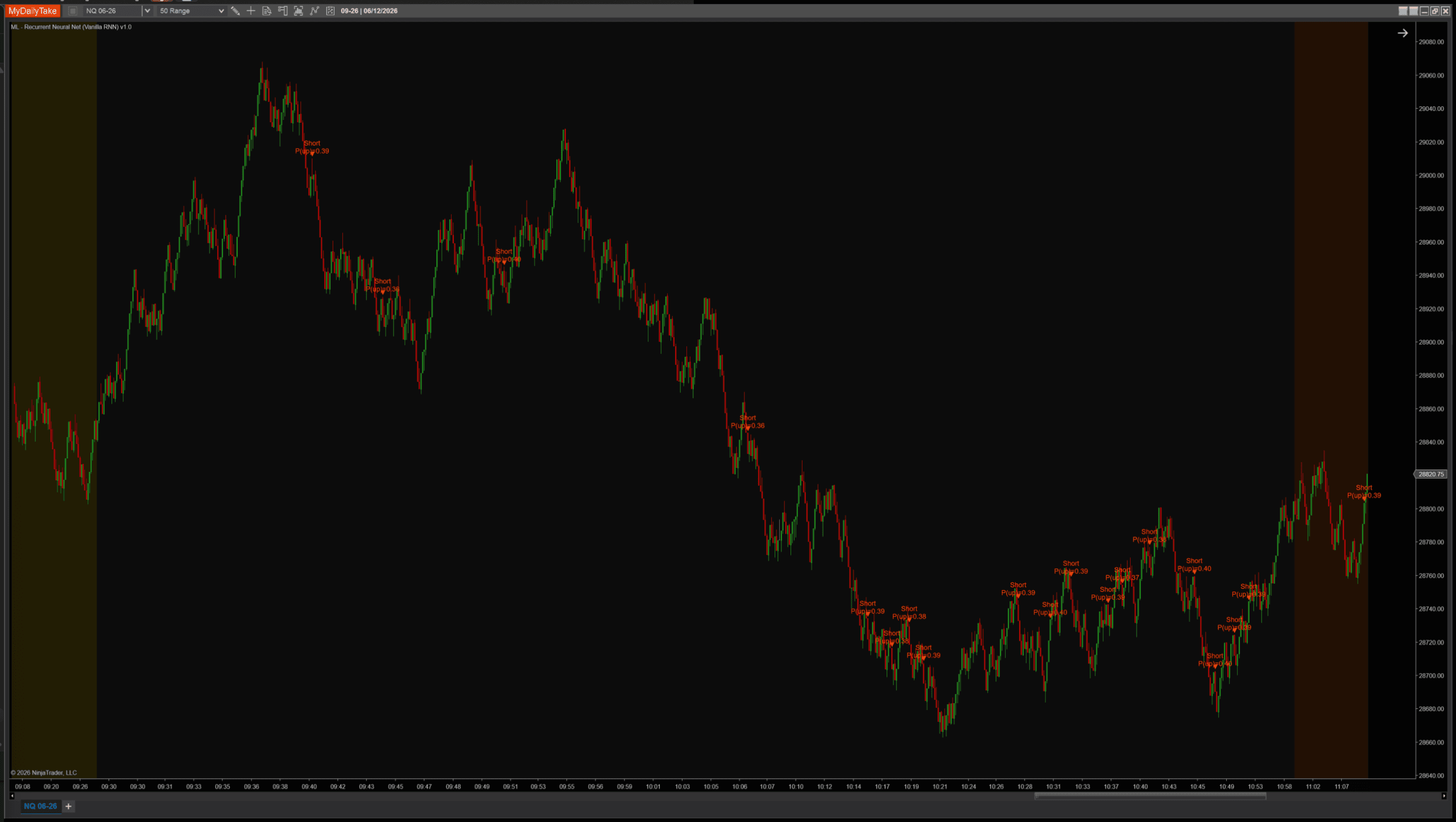
Default settings (BpttWindow = 10). A long near the open, shorts through the morning top and the afternoon range.
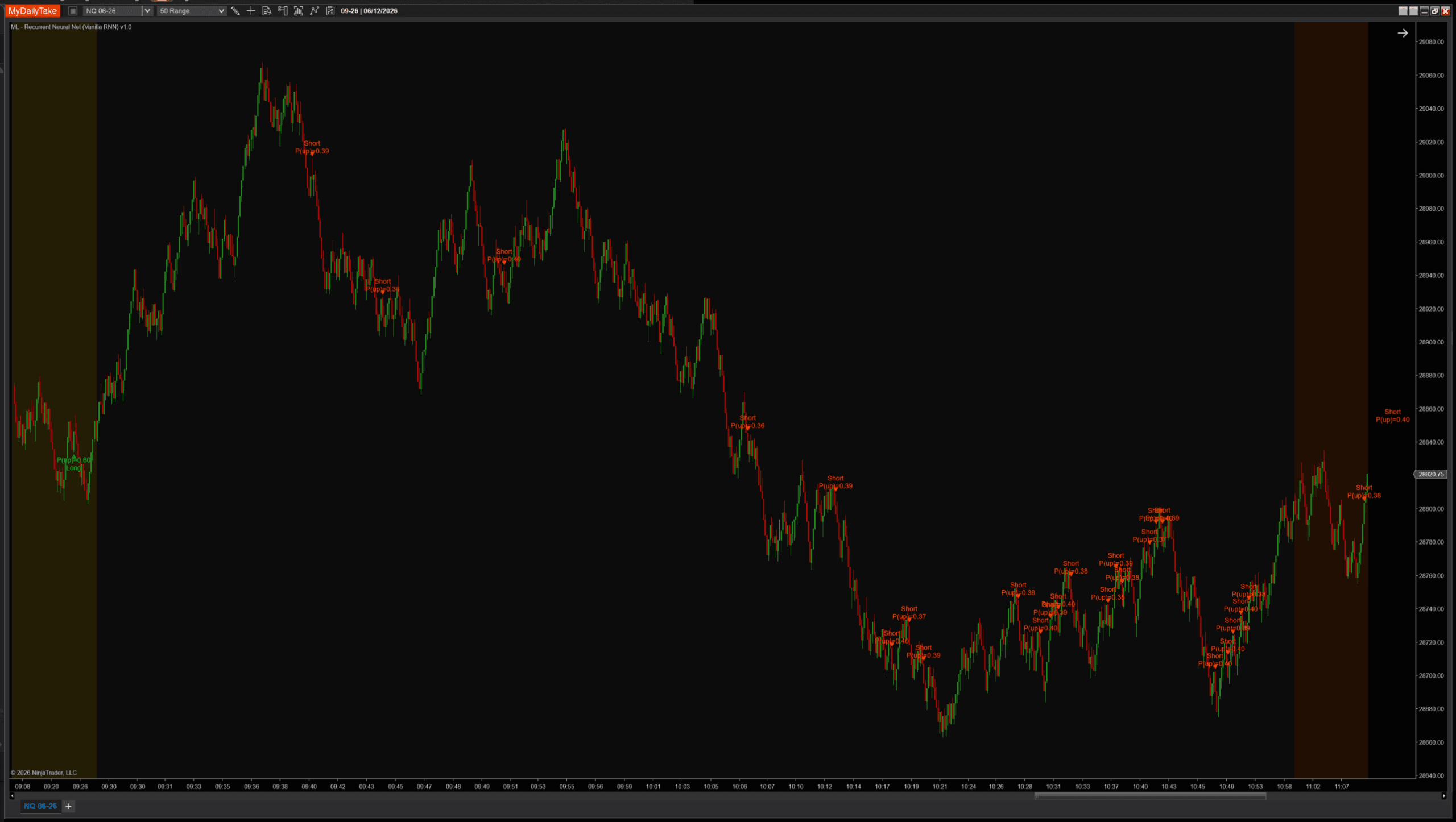
BpttWindow = 3 (short memory). Nearly the same signal set as the default.
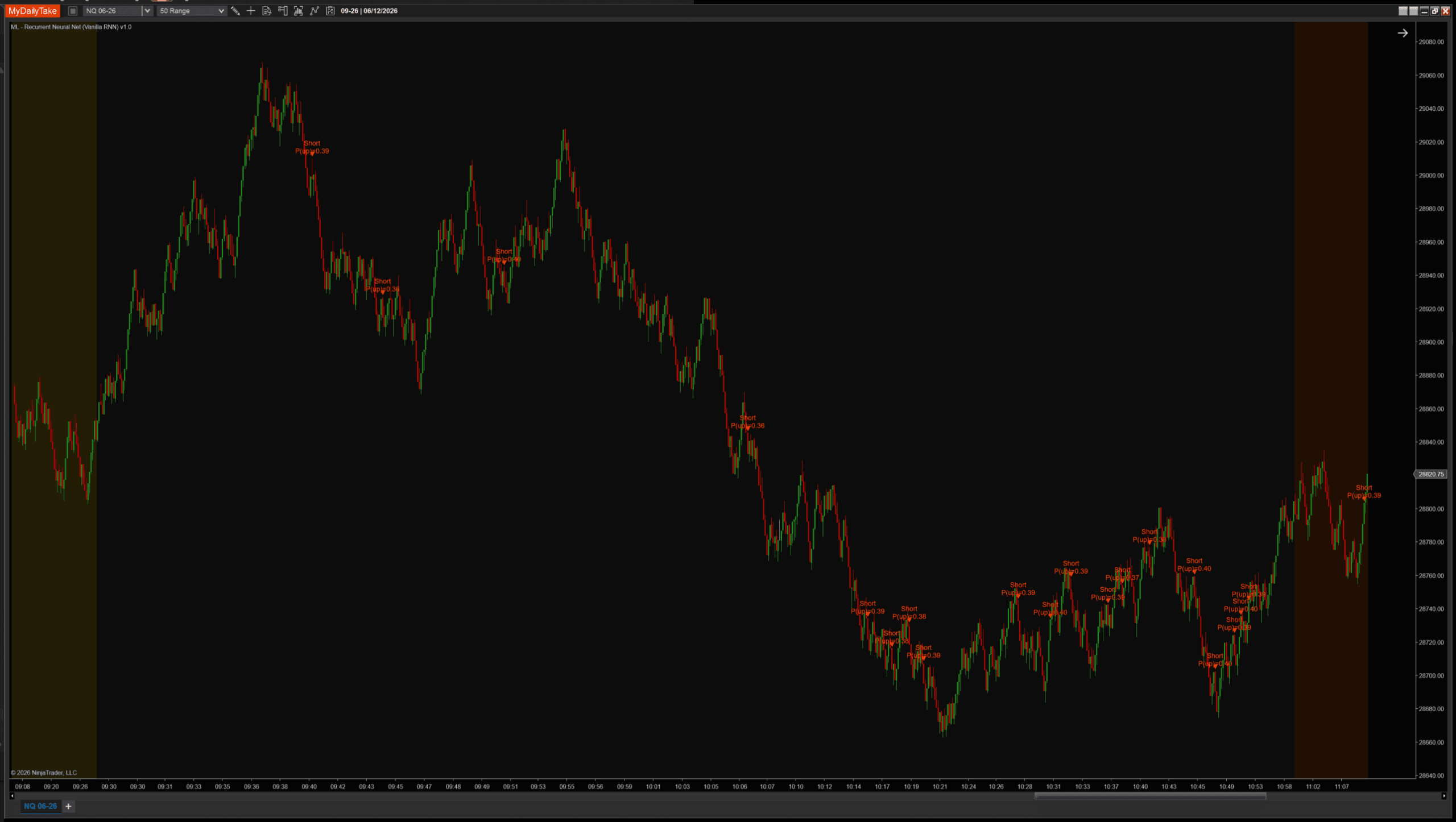
BpttWindow = 25 (long memory). Still almost the same chart.
Three windows spanning an 8× range — 3 bars to 25 — and the signals barely move. That is not a flaw in the screenshots; it is the vanishing gradient made visible. By the time the backward pass reaches bar 11, 15, or 25, the gradient has been multiplied down so far that those extra bars contribute almost nothing to what the weights learn. A 25-bar window ends up training on much the same short-range structure a 3-bar window does — it just spends more compute to get there. If you want a model that genuinely behaves differently with a longer horizon, you need an architecture that protects the gradient. That is the LSTM, next post.
⚙️ Settings
The indicator’s settings are grouped into five categories. Architecture sets the network shape and the BPTT window. Learning controls the labeling and the L2 penalty. Features controls what the model sees. Signal controls when triangles fire. Display is cosmetic-only.
Architecture
| Parameter | Description |
|---|---|
| Hidden Size | Number of neurons in the recurrent hidden layer. Each bar updates an H-dimensional hidden-state vector that persists across bars — this is the network's memory. Larger H = more memory capacity but more parameters to train. Default 8. |
| BPTT Window (bars) | Number of past bars the network is unrolled through when computing gradients (truncated Backpropagation Through Time). Bigger window = the model can in principle learn longer-range dependencies, but each training step costs more compute and the vanishing gradient limits how much the oldest bars actually contribute. Default 10. |
| Random Seed | Seed for the random weight initialization (when Weight Init = Random). The same seed produces the same starting weights — useful for reproducible testing or comparing settings fairly. |
Learning
| Parameter | Description |
|---|---|
| Learning Rate | Step size for each weight update. RNN training is more sensitive to learning rate than feedforward training because gradients compound across the BPTT window. Start at 0.005 and lower it first if training looks unstable. |
| Regularization Lambda (L2) | L2 penalty on weight magnitude. Pulls weights gently toward zero each update so they don't drift to extreme values. Applied to the weight matrices only, not the biases. Recommended 0.0001 to 0.001; default 0.0005. |
| Label Horizon (bars) | How many bars ahead the realized direction is observed. The model updates each bar using the prediction from N bars ago, whose forward outcome is now known — this keeps training look-ahead-safe. |
| Weight Init | Zero starts every weight at 0 — but the recurrent matrix would then have nothing to propagate and all neurons would learn identical weights (the symmetry problem). Random is strongly recommended; it uses Xavier/Glorot scaling tuned for tanh activations. |
| Label Mode | How the training label is defined. CloseToClose: y = 1 if Close at the end of the Label Horizon window is above Close at the training bar. FavorableExcursion: y = 1 if the long-side favorable move beat the short-side move during the window (uses bar highs/lows); bars below Min Favorable Move are skipped as chop. |
| Min Favorable Move (ATRs) | ONLY USED WHEN Label Mode = FavorableExcursion. Minimum favorable excursion (in ATRs at entry) required during the post-bar window for the model to update on that bar. |
Features
| Parameter | Description |
|---|---|
| MA Period | Period of the moving average used in the distance-from-MA feature, and the smoothing window for the ATR regime-ratio feature. |
| ATR Period | Period of the ATR used to scale every feature into volatility units, so distance comparisons stay consistent across regimes. |
| Slope Lookback (bars) | Number of bars over which the slope feature is measured: (Close[0] − Close[N]) / ATR. |
| Normalize Features (Z-Score) | Master toggle for z-score normalization. When ON, each feature is rescaled against its own historical rolling stats. Recommended ON. |
| Normalization Lookback (bars) | Window used to compute the rolling mean and standard deviation that z-score the features. Each bar uses its own local-time stats. |
Signal
| Parameter | Description |
|---|---|
| Min Probability Edge | How far the predicted probability of an up move must be from 0.5 before a signal fires. 0.10 means a long fires when P(up) > 0.60 and a short fires when P(up) < 0.40. |
| Signal Cooldown (bars) | Minimum number of bars between consecutive signals. Higher values space signals out so the chart stays readable. |
Display
| Parameter | Description |
|---|---|
| Marker Offset (ticks) | Vertical offset of the signal triangle from the bar's high (shorts) or low (longs), in ticks. |
| Label Offset (ticks) | Distance from the bar to the text label, in ticks. Should be larger than Marker Offset so the label sits beyond the triangle. |
| Show Labels | Render the predicted-probability label beside each signal triangle. |
| Label Font Size | Font size for the signal labels. |
One note on Learning Rate: RNN training is more sensitive to it than feedforward training, because gradients compound across the BPTT window. The default of 0.005 is deliberately conservative. If training looks unstable — signals flickering wildly bar to bar — lower it before changing anything else.
🎚️ Pairing With a Regime Filter
Same defensive pattern as the prior posts. An RSI(14) above or below 50 vetoes counter-trend signals, so the model is only allowed to fire in the direction of the broader trend:
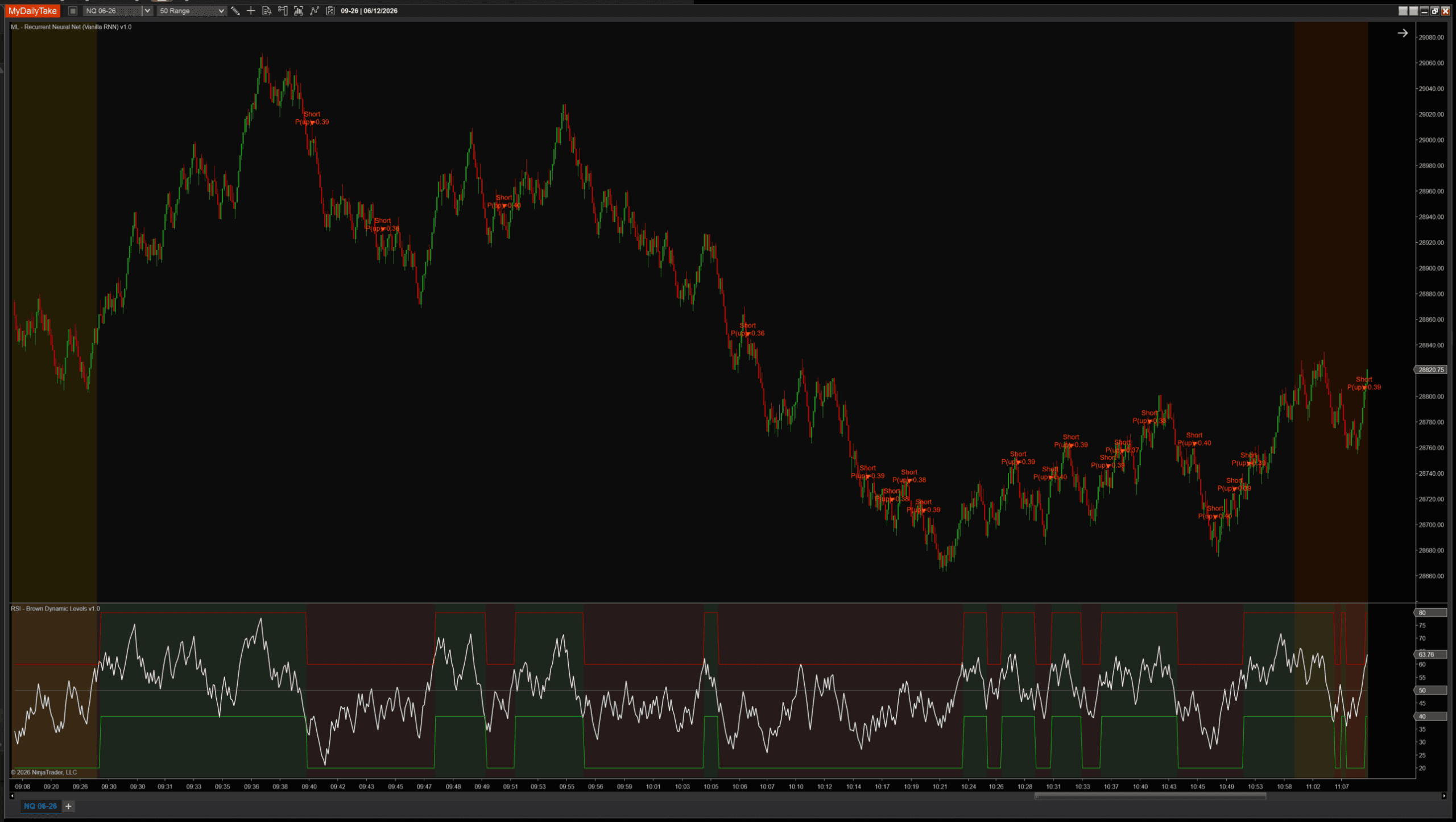
The RNN’s raw signal is a probability; the regime filter is a separate, far simpler model. Combining a learned signal with a transparent rule-based veto is a dependable way to keep an online learner from fighting the obvious trend.
🛠️ Using It in a Strategy
The indicator exposes its outputs as public Series so a strategy can consume the model directly, without re-deriving anything:
Public Outputs
| Output | Type | Purpose |
|---|---|---|
| ProbabilityUpSeries |
Series | The model's predicted probability of an up move — the post-sigmoid output. Range [0, 1]. |
| ConfidenceSeries |
Series | |P(up) − 0.5| × 2 — distance from a coin-flip, scaled to [0, 1]. 0 = uncertain, 1 = maximum conviction. |
| IsLongSignalSeries |
Series | True on bars where the prediction passes the probability gate AND the cooldown — a long signal fires. |
| IsShortSignalSeries |
Series | True on bars where the prediction passes the probability gate AND the cooldown — a short signal fires. |
Below is a working strategy that combines the model’s signal with the RSI regime filter from the previous section — a long is allowed only when the model predicts up and RSI is above 50, and the mirror for shorts:
private MlNeuralNetRnn nn;
private RSI rsi;
protected override void OnStateChange()
{
if (State == State.SetDefaults)
{
Name = "RnnRsiTrendFollower";
Calculate = Calculate.OnBarClose;
}
else if (State == State.DataLoaded)
{
nn = MlNeuralNetRnn(
hiddenSize: 8,
bpttWindow: 10,
randomSeed: 42,
learningRate: 0.005,
regularizationLambda: 0.0005,
labelHorizon: 2,
weightInit: MlNeuralNetRnn_WeightInitMode.Random,
labelMode: MlNeuralNetRnn_LabelMode.CloseToClose,
minFavorableMoveAtrs: 1.0,
maPeriod: 8,
atrPeriod: 50,
slopeLookback: 2,
normalizeFeatures: true,
normalizationLookback: 200,
minProbabilityEdge: 0.10,
signalCooldownBars: 3);
rsi = RSI(14, 3);
}
}
protected override void OnBarUpdate()
{
// The indicator gates its own signals through warmup; this is a safety margin.
if (CurrentBar < 350) return;
// Long: model predicts up AND RSI confirms the uptrend regime.
if (nn.IsLongSignalSeries[0] && rsi[0] > 50)
EnterLong("NN Long");
// Short: model predicts down AND RSI confirms the downtrend regime.
if (nn.IsShortSignalSeries[0] && rsi[0] < 50)
EnterShort("NN Short");
}
📝 The Honest Validation Talk (Still)
The recurrent hidden state makes this model strictly more expressive than its feedforward siblings — and that cuts both ways. A model with memory has more capacity to fit noise, not just signal, and an online learner that is continuously updating is a moving target: “accuracy over the last N bars” averages over many different effective models. The hidden state adds one more wrinkle — it means the model’s behavior on any given bar depends on a stretch of history that a simple bar-by-bar backtest does not isolate. None of that is a reason to avoid the model. It is a reason to evaluate it honestly: walk-forward across multiple regimes is still the only honest evaluation, and the work scales with how seriously you intend to trust the result.
📦 Download
Install:
- Download the .zip file above.
- In NinjaTrader 8, go to Tools → Import → NinjaScript Add-On.
- Select the downloaded .zip file.
- The indicator will appear under Indicators → indMyDailyTake → ML – Recurrent Neural Net (Vanilla RNN) v1.0 on your chart.
🎉 Prop Trading Discounts
💥89% off at Bulenox.com with the code MDT89
This is the sixth installment of the Learn NinjaScript ML series. Post 1 covered k-Nearest Neighbors, Post 2 online logistic regression, Post 3 added a single hidden layer, Post 4 extended to configurable depth, and Post 5 replaced plain SGD with the Adam optimizer and mini-batch training. Post 6 (this one) added a recurrent hidden state and truncated Backpropagation Through Time — the network’s first real memory. Post 7 takes on the vanishing gradient head-on with the LSTM.