ML — Adam Optimizer + Mini-Batch: Stable Training for NinjaTrader 8
The prior post let you stack any number of hidden layers — but every weight update was still plain stochastic gradient descent: one update per bar, one fixed step size for every weight. Plain SGD is the simplest possible training rule, and it works on shallow networks, but two things tend to go wrong at depth or under noisy data:
- Every weight gets the same step size. A weight that’s been hammered by a noisy gradient direction gets the same learning rate as a weight that’s been steady — even though one needs damping and the other doesn’t.
- Single-bar gradient noise. Online learning applies one bar’s gradient at a time. On a noisy bar, the entire network’s weights move in a direction the very next bar may try to reverse.
This post fixes both. The Adam optimizer gives each weight its own adaptive learning rate. Mini-batch training averages the per-bar gradient noise away before applying any update. Together they turn the wobbly online learner into a stably-trained model — same architecture, same features, same labels, fundamentally better convergence.
⚖️ Plain SGD vs Adam — Two Update Rules
The plain SGD update rule from the prior posts was a single line: w ← w − lr · g. Every weight, every step, same formula. Adam’s update is built around two extra running averages per weight — and that’s the entire idea.

That ratio in Adam’s update — m̂ / (√v̂ + ε) — is where the per-weight adaptation lives. m̂ is the bias-corrected momentum (a running average of the gradient). v̂ is the bias-corrected variance (a running average of the squared gradient). Their ratio is large when momentum is consistent and variance is low, small when the gradient has been noisy. Each weight scales its own step based on its own recent history.
🌀 Adam’s Two Moments
Adam keeps two exponential running averages per parameter:
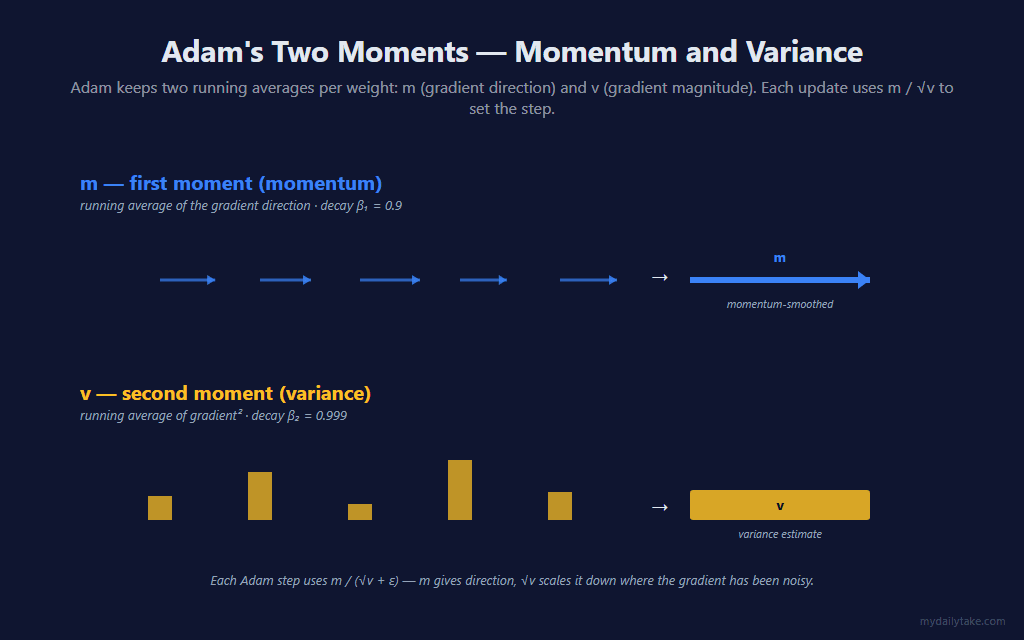
- m (first moment / momentum) — a running average of the gradient itself. With β₁ = 0.9, each step nudges the running average toward the latest gradient by 10%. The result is a smoother direction signal that resists single-bar reversals. This is the “momentum” intuition from physics — past gradients keep pushing in the same direction.
- v (second moment / variance) — a running average of the squared gradient. With β₂ = 0.999, this changes very slowly and captures how variable the gradient has been over many bars. Weights with consistently large gradients build up large v; weights with noisy gradients also build up large v (because squaring kills the sign).
The Adam step uses these together as m / (√v + ε). If a weight has both consistent direction (large m) and steady magnitude (predictable v), the ratio is large — confident step. If a weight has been noisy (m small from sign cancellation, v large from squared magnitudes), the ratio is small — damped step. This is per-weight adaptive learning, and it’s why a single global learning rate works across an entire network.
The “bias correction” in m̂ = m / (1 − β₁ᵗ) compensates for the running averages being initialized at zero. Without it, the very first updates would be tiny (because m hasn’t had time to accumulate from zero). The bias correction normalizes early updates and gracefully fades to identity once β₁ᵗ approaches zero.
🔁 Mini-Batch Averaging
The second change in this post is independent of Adam: instead of applying a weight update on every training-eligible bar, we accumulate gradients across BatchSize bars and apply one averaged update.
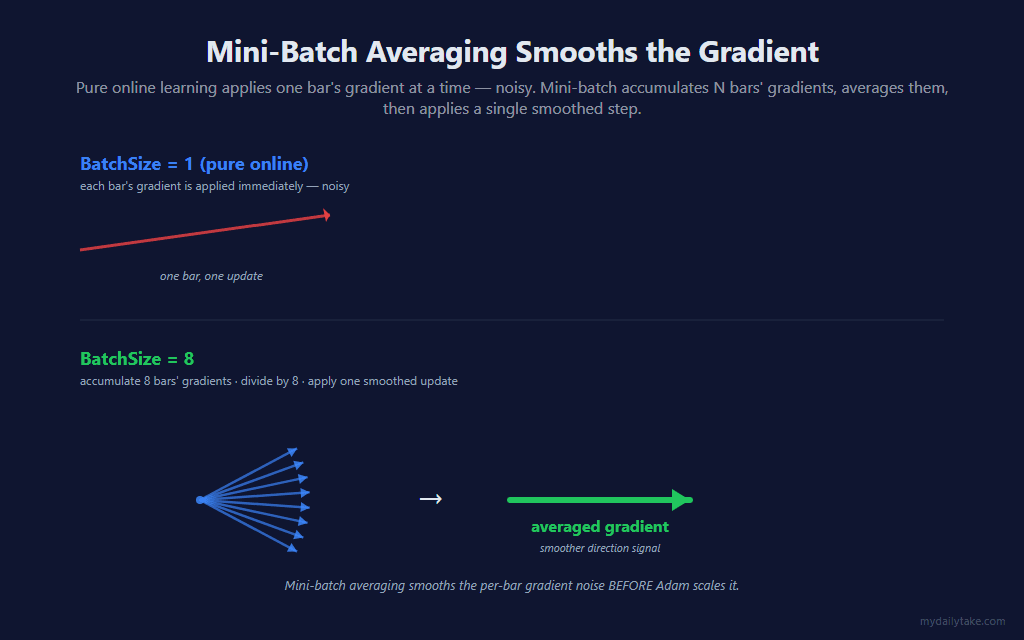
The math is straightforward — sum the gradients across N bars, divide by N, apply that as a single update. The effect is that the noisy per-bar gradient direction gets averaged into a smoother direction estimate before Adam’s variance scaling kicks in. The two improvements compound: mini-batch reduces noise upstream, Adam scales the remaining signal per-weight downstream.
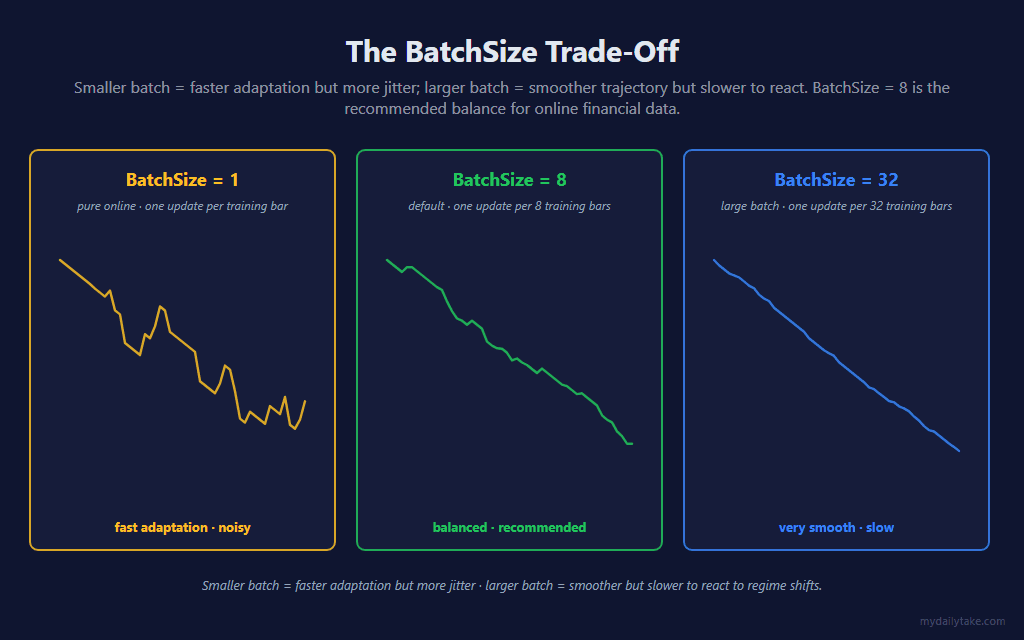
Larger BatchSize = smoother but slower to react. Smaller BatchSize = noisier but faster to adapt to regime shifts. BatchSize = 8 is the default — enough averaging to smooth single-bar noise, few enough bars per update that the model still tracks recent regime within a session. Set BatchSize = 1 to disable mini-batching and run pure-online Adam; set it to 32 or higher when you want maximum smoothness and don’t mind slower convergence.
📉 Descending the Loss Landscape
Same starting weights, same training data, same target — only the optimizer changes. Plain SGD wobbles toward the minimum because every direction gets the same step size. Adam scales each direction by its variance, so noisy directions damp and the descent stays on course:
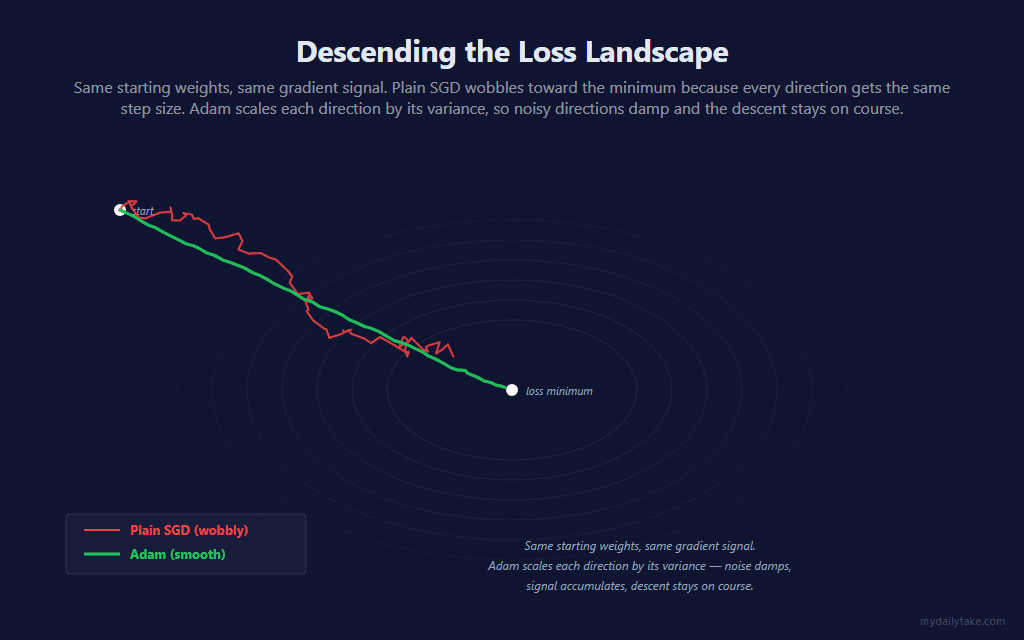
The smoother trajectory is not just cosmetic — it matters because online learning on financial bars doesn’t have the luxury of running many epochs over the same data. Each bar is one shot. A wobbly path takes more bars to reach the same loss; a smooth path reaches it sooner and stays there.
➡️ The Forward Pass (Unchanged)
The forward pass is identical to the multi-hidden-layer sibling. The optimizer only changes how weights are updated, not how the forward computation runs:
// Forward pass — identical to the multi-hidden-layer sibling. The optimizer
// only changes how weights are UPDATED, not how the forward computation runs.
// inputs -> layer 0 -> ... -> output sigmoid.
private double ForwardPass(double[] inputs)
{
for (int l = 0; l < numHiddenLayers; l++)
{
double[] inputToLayer = (l == 0) ? inputs : hiddenAct[l - 1];
int sizeIn = inputToLayer.Length;
int sizeOut = layerSizes[l];
for (int h = 0; h < sizeOut; h++)
{
double z = bh[l][h];
for (int k = 0; k < sizeIn; k++)
z += Wh[l][h][k] * inputToLayer[k];
hiddenPre[l][h] = z;
hiddenAct[l][h] = Activate(z);
}
}
int last = numHiddenLayers - 1;
double zOut = bo;
for (int h = 0; h < layerSizes[last]; h++)
zOut += Wo[h] * hiddenAct[last][h];
return Sigmoid(zOut);
}
🧮 Accumulating Gradients
The backward pass is also the same chain rule — but instead of applying the gradient as a weight update immediately, it’s added to a per-parameter accumulator. The actual weight update is deferred until the mini-batch is full.
// AccumulateGradients — same chain-rule backprop as the multi-layer sibling,
// but instead of applying weight updates immediately, the gradients are ADDED
// to running accumulators. The actual weight update happens later, once we've
// accumulated BatchSize bars' worth (in ApplyAdamUpdate below).
// L2 regularization is also accumulated, so the final per-parameter gradient
// will be the mini-batch mean of (data gradient + λ·w).
private void AccumulateGradients(double[] inputs, double pTrain, double y)
{
double error = pTrain - y;
int last = numHiddenLayers - 1;
for (int h = 0; h < layerSizes[last]; h++)
dHiddenAct[last][h] = error * Wo[h];
for (int l = last; l >= 0; l--)
{
int sizeOut = layerSizes[l];
int sizeIn = (l == 0) ? NumFeatures : layerSizes[l - 1];
double[] inputToLayer = (l == 0) ? inputs : hiddenAct[l - 1];
for (int h = 0; h < sizeOut; h++)
dHiddenPre[l][h] = dHiddenAct[l][h] * ActivationDerivative(hiddenPre[l][h], hiddenAct[l][h]);
if (l > 0)
{
for (int k = 0; k < sizeIn; k++) dHiddenAct[l - 1][k] = 0;
for (int h = 0; h < sizeOut; h++)
{
double dpre = dHiddenPre[l][h];
for (int k = 0; k < sizeIn; k++)
dHiddenAct[l - 1][k] += dpre * Wh[l][h][k];
}
}
// Accumulate gradients into gWh[l] / gbh[l] — no weight update yet.
for (int h = 0; h < sizeOut; h++)
{
double dpre = dHiddenPre[l][h];
for (int k = 0; k < sizeIn; k++)
gWh[l][h][k] += dpre * inputToLayer[k] + RegularizationLambda * Wh[l][h][k];
gbh[l][h] += dpre;
}
}
// Accumulate output-layer gradients.
for (int h = 0; h < layerSizes[last]; h++)
gWo[h] += error * hiddenAct[last][h] + RegularizationLambda * Wo[h];
gbo += error;
}
Notice the regularization term RegularizationLambda · Wh[l][h][k] is added to the accumulator on every bar. After dividing by gAccumCount in the update step, that gives an effective L2 contribution of exactly λ · w per parameter per update — same total effect as the online SGD with L2 from the prior posts.
⚡ Applying the Adam Update
When gAccumCount reaches BatchSize, we apply one Adam update per parameter using the mean of the accumulated gradients. The same Adam math runs for every parameter — hidden weights, hidden biases, output weights, output bias — using each parameter’s own m and v running averages:
// ApplyAdamUpdate — runs once every BatchSize training-eligible bars.
// Per-parameter Adam update rule:
// m_t = β1 · m_{t-1} + (1 - β1) · g
// v_t = β2 · v_{t-1} + (1 - β2) · g²
// m_hat = m_t / (1 - β1^t)
// v_hat = v_t / (1 - β2^t)
// w -= lr · m_hat / (sqrt(v_hat) + ε)
// Bias-correction terms (m_hat, v_hat) compensate for the moving averages
// being initialized at zero — without them, the first updates would be tiny.
private void ApplyAdamUpdate()
{
adamStep++;
double invN = 1.0 / Math.Max(1, gAccumCount); // mini-batch averaging
double biasCorr1 = 1.0 - Math.Pow(Beta1, adamStep);
double biasCorr2 = 1.0 - Math.Pow(Beta2, adamStep);
// Hidden layers.
for (int l = 0; l < numHiddenLayers; l++)
{
int sizeIn = (l == 0) ? NumFeatures : layerSizes[l - 1];
int sizeOut = layerSizes[l];
for (int h = 0; h < sizeOut; h++)
{
for (int k = 0; k < sizeIn; k++)
{
double g = gWh[l][h][k] * invN;
mWh[l][h][k] = Beta1 * mWh[l][h][k] + (1.0 - Beta1) * g;
vWh[l][h][k] = Beta2 * vWh[l][h][k] + (1.0 - Beta2) * g * g;
double mHat = mWh[l][h][k] / biasCorr1;
double vHat = vWh[l][h][k] / biasCorr2;
Wh[l][h][k] -= LearningRate * mHat / (Math.Sqrt(vHat) + Epsilon);
gWh[l][h][k] = 0;
}
double gb = gbh[l][h] * invN;
mbh[l][h] = Beta1 * mbh[l][h] + (1.0 - Beta1) * gb;
vbh[l][h] = Beta2 * vbh[l][h] + (1.0 - Beta2) * gb * gb;
double mbHat = mbh[l][h] / biasCorr1;
double vbHat = vbh[l][h] / biasCorr2;
bh[l][h] -= LearningRate * mbHat / (Math.Sqrt(vbHat) + Epsilon);
gbh[l][h] = 0;
}
}
// Output layer — same Adam math.
int last = numHiddenLayers - 1;
for (int h = 0; h < layerSizes[last]; h++)
{
double g = gWo[h] * invN;
mWo[h] = Beta1 * mWo[h] + (1.0 - Beta1) * g;
vWo[h] = Beta2 * vWo[h] + (1.0 - Beta2) * g * g;
double mHat = mWo[h] / biasCorr1;
double vHat = vWo[h] / biasCorr2;
Wo[h] -= LearningRate * mHat / (Math.Sqrt(vHat) + Epsilon);
gWo[h] = 0;
}
double goB = gbo * invN;
mbo = Beta1 * mbo + (1.0 - Beta1) * goB;
vbo = Beta2 * vbo + (1.0 - Beta2) * goB * goB;
bo -= LearningRate * (mbo / biasCorr1) / (Math.Sqrt(vbo / biasCorr2) + Epsilon);
gbo = 0;
}
The adamStep counter increments once per update (not once per bar). Bias correction uses this counter as the exponent — 1 − β₁^adamStep approaches 1 as the optimizer runs, which means the bias correction is most aggressive in the first few updates (when m and v are still close to zero) and gracefully fades to identity later.
🔁 The Training Loop
The mini-batch accumulator is a tiny state machine inside OnBarUpdate: each training-eligible bar adds to the running gradient sum and increments a counter. Once the counter hits BatchSize, we flush via Adam and reset.
// Training loop inside OnBarUpdate — mini-batch accumulator state machine.
// Each training-eligible bar appends its gradient to the running accumulator.
// Once gAccumCount reaches BatchSize, we apply one Adam update using the
// mean of the accumulated gradients, then reset the accumulator.
if (trainThisBar)
{
GetFeaturesInto(scratchRaw, trainBar);
NormalizeInto(scratchNorm, scratchRaw, trainBar);
// Forward pass at trainBar with current weights.
double pTrain = ForwardPass(scratchNorm);
// Backward pass — adds this bar's gradients to the mini-batch.
AccumulateGradients(scratchNorm, pTrain, y);
gAccumCount++;
// Flush: apply Adam update once BatchSize bars have been accumulated.
if (gAccumCount >= BatchSize)
{
ApplyAdamUpdate();
gAccumCount = 0;
}
}
This is the only thing the higher-level training loop needs to know about — everything else lives inside AccumulateGradients and ApplyAdamUpdate. The look-ahead-safety mechanism from the prior posts (training on the bar from LabelHorizon ago, predicting on the current bar) is unchanged.
📊 What This Looks Like on a Chart
Same indicator, same architecture, same session. Only BatchSize changes:
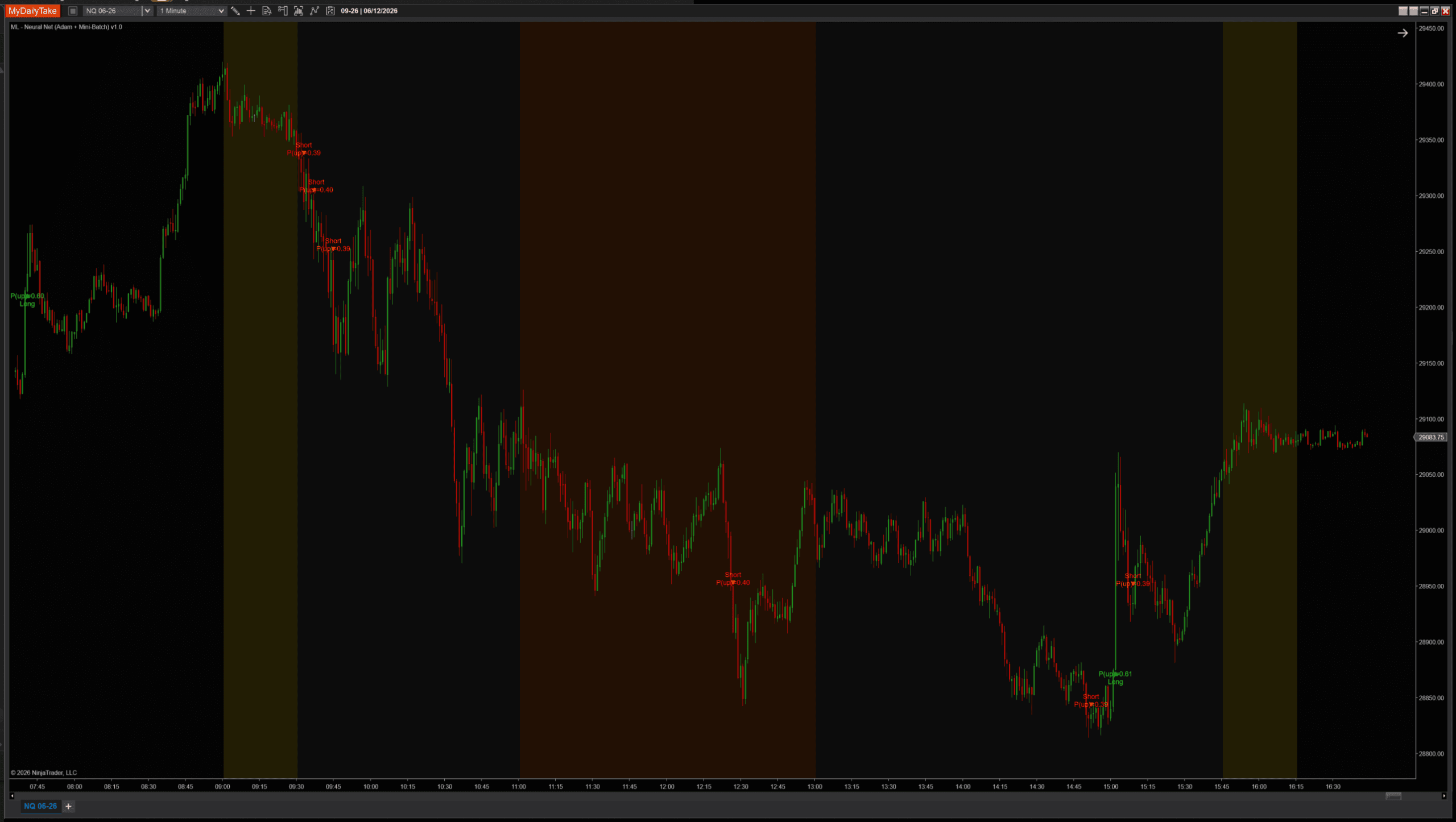
Default settings (BatchSize = 8). Balanced signal density across the session.
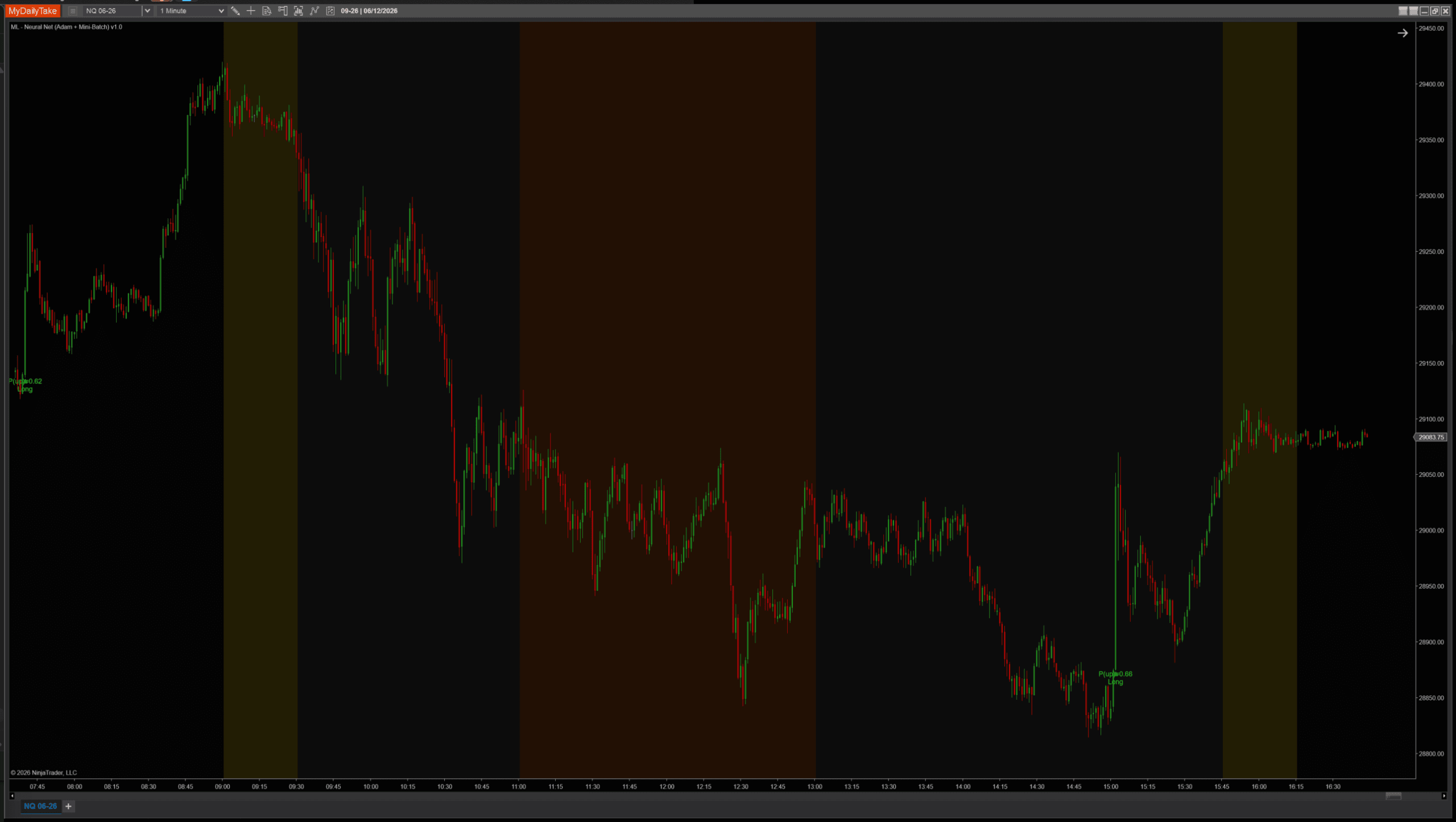
BatchSize = 1 (pure online Adam, no mini-batch averaging). Many fewer signals — Adam alone is selective without the averaging upstream.
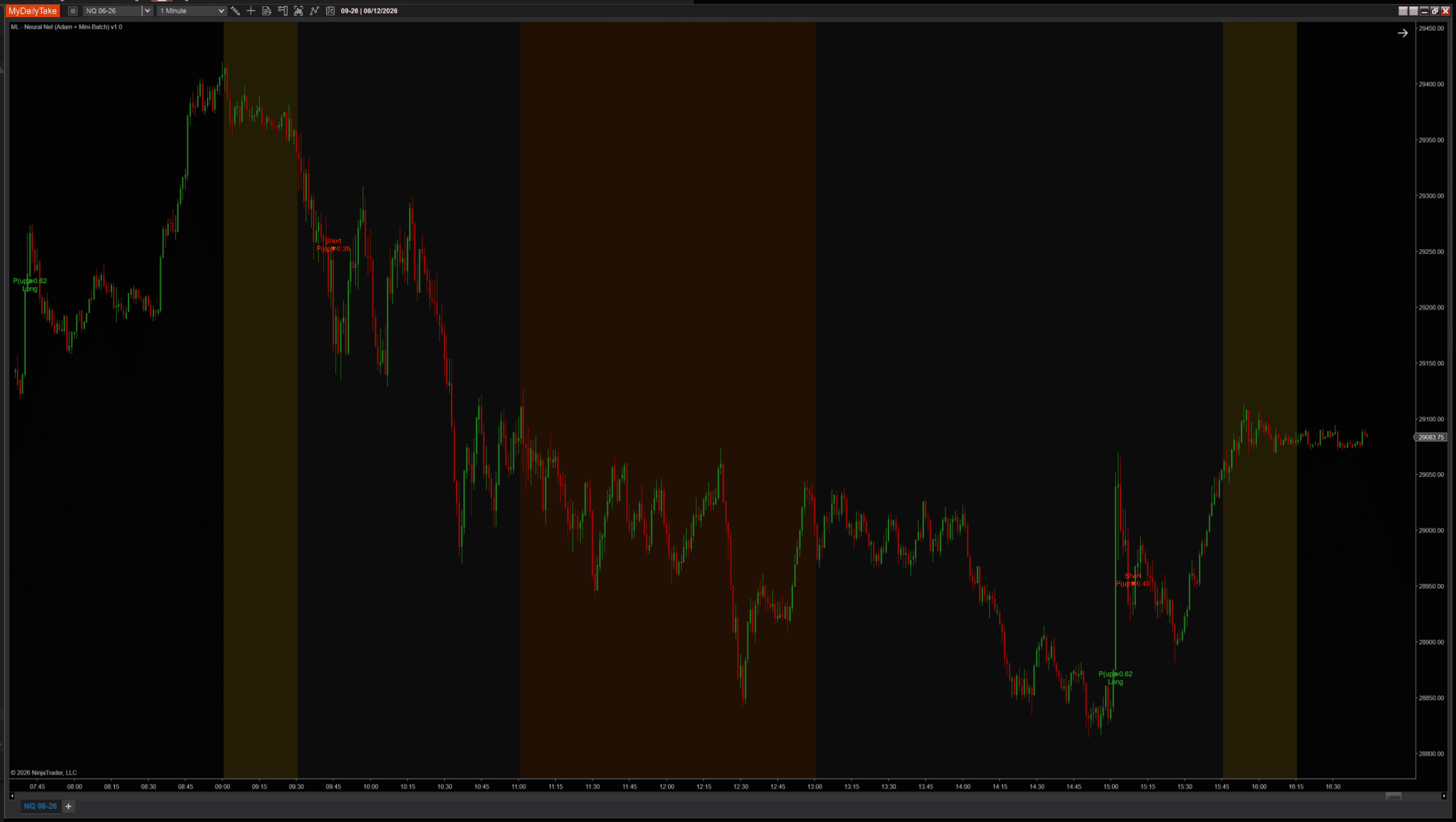
BatchSize = 20. Fewer signals than the default — the larger batch needs more bars to accumulate enough updates to fire confident signals.
The story across the three: more updates per session (smaller batch) doesn’t automatically mean more signals — Adam’s per-weight adaptation can damp updates aggressively when the gradient has been noisy. BatchSize = 8 sits in the sweet spot for online financial data on this feature set.
⚙️ Settings
The indicator’s settings are grouped into six categories. Architecture picks the network shape. Learning controls the labeling and the L2 penalty. Optimizer is new in this post — it’s where Adam’s hyperparameters live. Features controls what the model sees. Signal controls when triangles fire. Display is cosmetic-only.
Architecture
| Parameter | Description |
|---|---|
| Hidden Layer Sizes | Per-layer neuron counts as a list of integers. Any common separator works — comma, space, hyphen, x, semicolon. Examples: '6' = one hidden layer of 6 neurons. '8, 6' = two hidden layers (8 then 6). '10, 6, 4' = three hidden layers. Each value must be ≥ 2. With Adam, slightly deeper networks train more reliably than they do with plain SGD, but the practical lift on a 3-feature problem still plateaus around 2 layers. Invalid input falls back to default '8, 6' and logs a warning to the NT Output window. |
| Hidden Activation | Activation function on EVERY hidden layer. ReLU is the recommended default — it pairs naturally with Adam and avoids vanishing-gradient problems at depth. Tanh and Sigmoid also work but produce smaller gradients at depth. |
| Random Seed | Seed for the random weight initialization (when Weight Init = Random). Same seed = same starting weights. Useful for fair comparisons between architectures or optimizer settings. |
Learning
| Parameter | Description |
|---|---|
| Learning Rate | Adam's base learning rate. Adam is much less sensitive to this than plain SGD because of the adaptive per-parameter scaling, but the value still sets the overall step magnitude. 0.001 is the canonical Adam default; for online financial data, 0.001-0.005 works well. |
| Regularization Lambda (L2) | L2 penalty on weight magnitude. Pulls weights gently toward zero each update so they don't drift to extreme values. Recommended 0.0001 to 0.001. Default 0.0001. |
| Label Horizon (bars) | How many bars ahead the realized direction is observed. The model updates each bar using the feature vector from N bars ago, whose forward direction is now known — this keeps training look-ahead-safe. |
| Weight Init | Random init is essentially required — Adam's adaptive scaling can't recover from the symmetry of all-zero weights. Random uses activation-aware scaling per layer: He for ReLU, Xavier/Glorot for tanh and sigmoid. |
| Label Mode | How the training label is defined. CloseToClose: y = 1 if Close at end of LabelHorizon window is above Close at trainBar. FavorableExcursion: y = 1 if MFE_long beat MFE_short during the window (uses bar highs/lows). Skips bars below Min Favorable Move (chop). Same semantics as the prior posts. |
| Min Favorable Move (ATRs) | ONLY USED WHEN Label Mode = FavorableExcursion. Minimum favorable excursion (in ATRs at entry) required during the post-bar window for the model to update. |
Optimizer
| Parameter | Description |
|---|---|
| Mini-Batch Size | Number of training-eligible bars to accumulate gradients over before applying an Adam update. 1 = pure online (one update per bar, like the prior posts). 5-20 = small mini-batches that smooth single-bar noise. Larger values trade adaptation speed for stability. Recommended 5-10 for online financial data; default 8. |
| Beta1 (momentum decay) | Exponential decay rate for Adam's first-moment estimate (the momentum / running gradient mean). Higher values = longer memory of past gradients. 0.9 is the canonical default; rarely needs tuning. |
| Beta2 (variance decay) | Exponential decay rate for Adam's second-moment estimate (the running gradient variance). Higher values = longer memory of past gradient magnitudes. 0.999 is the canonical default; rarely needs tuning. |
| Epsilon | Small constant added to Adam's variance term denominator to prevent division by zero. 1e-8 is the canonical default and rarely needs tuning. |
Features
| Parameter | Description |
|---|---|
| MA Period | Period of the moving average used in the distFromMa feature, and used as the smoothing window for the ATR regime ratio. |
| ATR Period | Period of the ATR used to scale every feature into volatility units, so distance comparisons stay consistent across regimes. |
| Slope Lookback (bars) | Number of bars over which the slope feature is measured: (Close[0] − Close[N]) / ATR. |
| Normalize Features (Z-Score) | Master toggle for z-score normalization. When ON, each feature is rescaled against its own historical rolling stats. Recommended ON. |
| Normalization Lookback (bars) | Window used to compute the rolling mean / stddev that z-score the features. Each bar uses its own local-time stats. |
Signal
| Parameter | Description |
|---|---|
| Min Probability Edge | How far the predicted probability of an up move must be from 0.5 before a signal fires. 0.10 means: long fires when P(up) > 0.60, short fires when P(up) < 0.40. |
| Signal Cooldown (bars) | Minimum bars between consecutive signals. Higher values space signals out so the chart stays readable. |
Display
| Parameter | Description |
|---|---|
| Marker Offset (ticks) | Vertical offset of the signal triangle from the bar's high (shorts) / low (longs), in ticks. |
| Label Offset (ticks) | Distance from the bar to the text label, in ticks. Should be larger than Marker Offset so the label sits beyond the triangle. |
| Show Labels | Render the predicted-probability label beside each signal triangle. |
| Label Font Size | Font size for the signal labels. |
🎚️ Pairing With a Regime Filter
Same defensive pattern as the prior posts. RSI(14) above/below 50 vetoes counter-trend signals. The Adam version’s signals are more selective than the plain-SGD multi-layer sibling, but the regime filter is still the simplest way to enforce trend alignment:
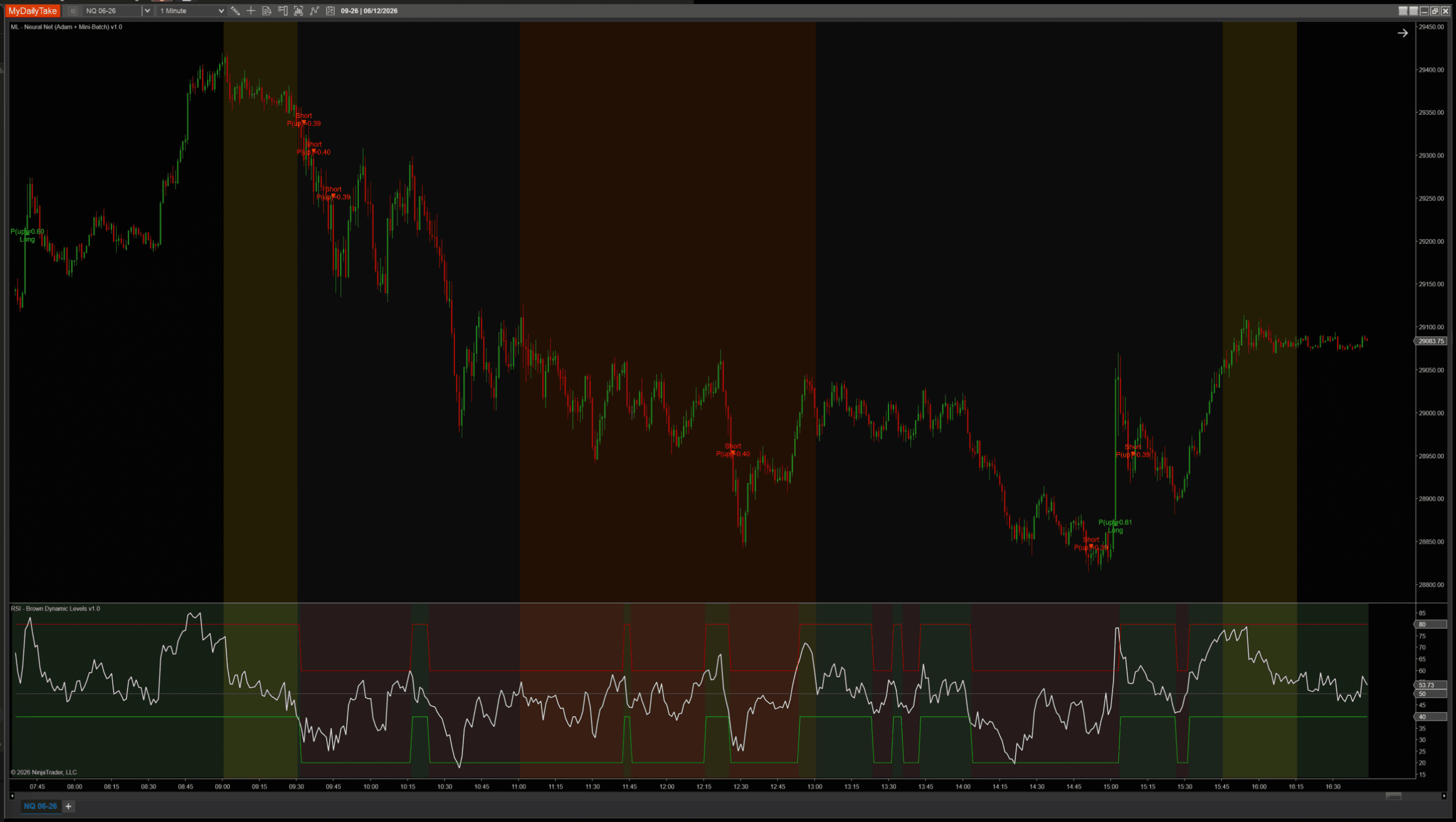
🛠️ Using It in a Strategy
Public Series exposed for strategy chaining:
Public Outputs
| Output | Type | Purpose |
|---|---|---|
| ProbabilityUpSeries |
Series | The model's predicted probability of an up move, post-sigmoid output layer. Range [0, 1]. |
| ConfidenceSeries |
Series | |P(up) − 0.5| × 2 — distance from coin-flip, scaled to [0, 1]. 0 = uncertain, 1 = maximum conviction. |
| IsLongSignalSeries |
Series | True on bars where prediction passes the probability gate AND cooldown — long signal fires. |
| IsShortSignalSeries |
Series | True on bars where prediction passes the probability gate AND cooldown — short signal fires. |
Below: working strategy combining the model’s signal with an RSI regime filter. Adam’s signals are typically fewer than plain SGD’s but more confident — adjust your strategy’s frequency expectations accordingly:
private MlNeuralNetAdam nn;
private RSI rsi;
protected override void OnStateChange()
{
if (State == State.SetDefaults)
{
Name = "AdamRsiTrendFollower";
Calculate = Calculate.OnBarClose;
}
else if (State == State.DataLoaded)
{
nn = MlNeuralNetAdam(
hiddenLayerSizes: "8, 6",
hiddenActivation: MlNeuralNetAdam_Activation.ReLU,
randomSeed: 42,
learningRate: 0.001,
regularizationLambda: 0.0001,
labelHorizon: 2,
weightInit: MlNeuralNetAdam_WeightInitMode.Random,
labelMode: MlNeuralNetAdam_LabelMode.CloseToClose,
minFavorableMoveAtrs: 1.0,
batchSize: 8,
beta1: 0.9,
beta2: 0.999,
epsilon: 1e-8,
maPeriod: 8,
atrPeriod: 50,
slopeLookback: 2,
normalizeFeatures: true,
normalizationLookback: 200,
minProbabilityEdge: 0.10,
signalCooldownBars: 3);
rsi = RSI(14, 3);
}
}
protected override void OnBarUpdate()
{
if (CurrentBar < 400) return; // longer warmup — Adam needs time to stabilize
// Long: model predicts up AND RSI confirms uptrend regime.
if (nn.IsLongSignalSeries[0] && rsi[0] > 50)
EnterLong("NN Long");
// Short: model predicts down AND RSI confirms downtrend regime.
if (nn.IsShortSignalSeries[0] && rsi[0] < 50)
EnterShort("NN Short");
}
📝 The Honest Validation Talk (Still)
Adam’s adaptive learning makes the model converge faster, but it doesn’t change the fundamental validation problem: an online-learning model is continuously changing, and “accuracy over the last N bars” averages over many different effective models. With Adam’s faster convergence, recent regime updates the model even more quickly than plain SGD, meaning even fewer past bars reflect the current behavior. Walk-forward across multiple regimes is the only honest evaluation, and the work scales with how seriously you want to trust the result.
📦 Download
Install:
- Download the .zip file above.
- In NinjaTrader 8, go to Tools → Import → NinjaScript Add-On.
- Select the downloaded .zip file.
- The indicator will appear under Indicators → indMyDailyTake → ML — Neural Net (Adam + Mini-Batch) v1.0 on your chart.
🎉 Prop Trading Discounts
💥89% off at Bulenox.com with the code MDT89
This is the fifth installment of the Learn NinjaScript ML series. Post 1 covered k-Nearest Neighbors, Post 2 online logistic regression, Post 3 added a single hidden layer, Post 4 extended to configurable depth. Post 5 (this one) replaced plain SGD with the Adam optimizer and added mini-batch training — the same architecture, but stably trained.